ID: 5dbd552c77ac441e7206e9cc
Image Captioning
Image Captioning based on show attend and tell
License: MIT License
Tags:
Model stats and performance
| Dataset Used | COCO |
| Framework | Tensorflow |
| OS Used | Linux |
| Publication | View |
Inference time in seconds per sample.
Screenshots
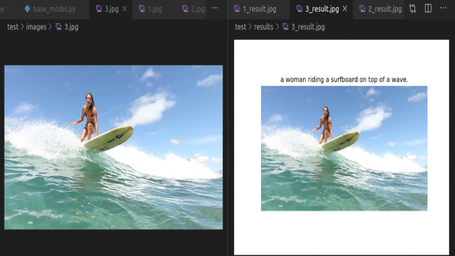
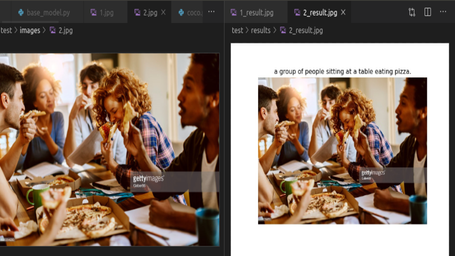
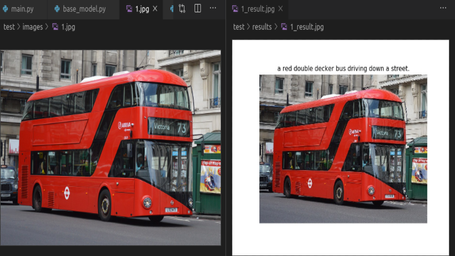
IMAGE CAPTIONING BASED ON SHOW ATTEND AND TELL
WHAT IS IT?
Automatically generating captions of an image is a task
very close to the heart of scene understanding — one of the primary goals of computer vision.This model takes a single raw image and generates a caption
y encoded as a sequence of 1-of-K encoded words.
y = {y1, . . . , yC } , yi ∈ R^K
where K is the size of the vocabulary and C is the length
of the caption.A convolutional neural network is used in order to extract a
set of feature vectors which we refer to as annotation vectors. The extractor produces L vectors, each of which is a D-dimensional representation corresponding to a part of the image.
HOW TO USE?
To run The Inference Script run this command
python run.py –phase –model_file –beam_size
SAMPLE COMMAND
python run.py --phase test --model_file 289999.npy --beam_size 3
| ARGUMENTS | DETAILS | HELP OPTIONS |
|---|---|---|
| –phase | Phase | Mention the phase of model |
| –model_file | model path | Mention the input model path |
| –beam_size | beam size | beams to consider |
WHAT ARE THE REQUIREMENTS?
To get all the requirements and dependencies installed run the command
For GPU - pip install -r gpu_requirements.txt
For CPU - pip install -r cpu_requirements.txt
Author View Profile
Views
Curious Mind with a Knack in Deep Learning
Rowing through
User Reviews
0 total ratings
Model has not been reviewed yet.
