
Stylumia - Demand Forecasting Hiring AI Challenge
Aim of this challenge is to forecast demand and inventory with a given dataset
Full Time

Welcome to Stylumia - Demand Forecasting Hiring AI Challenge!
This competition is provided as a way to explore different time series techniques on a relatively simple and clean dataset.
You are given 4 Seasons (SS17, SS18, AW17 and AW18) of store-Style-Size sales data, and asked to predict for the upcoming seasons (SS19 and AW19) of sales for all the Store-Style-Size combinations.
What's the best way to deal with seasonality? Should stores be modelled separately, or can you pool them together? Does deep learning work better than traditional models? Can either beat xgboost? This is a great competition to explore different models and test your skills in forecasting.
Please refer to the Submission Guidelines to understand the dataset and submission format.
Submission Guidelines
- You are required to submit your test set prediction file: output.csv - read below how to generate this file
- IPython Notebook describing your approach and the code. The notebook must be uploaded in the "My Submissions" section of this challenge.
Generating the output.csv:
The given dataset zip consists of 3 files:

- TRAIN.csv (Training Data)
- TEST.csv (Test Data on which predictions have to be made)
- Sample_Submission.csv (Sample file for final submission)
The aim of the challenge is to train a model for demand forecasting and make predictions on "TEST.csv" data for the following attributes:
- Sales_QTY
- NSV
The final output for submission should be a single "output.csv". The sample format is already given in "Sample_Submission.csv"(the challenge has been updated and only "NSV/Sales_QTY" has to be predicted now) for reference along with a screenshot below which displays the final attributes required in your submission.
Sample Submission CSV format:

------------------------------
Dataset Details:
Unique Transaction ID - Unique ID Associated with each Transaction
Transaction_Date - Transaction Date of the Sales Data
STORE_CODE - Represents the Unique Code for each Store / It can also be considered as the name of the Store.
Type Of Transaction - Type of the Sale Transaction, Either Returned or Sale
Style_ID - Represents the Style for which the Transaction has happened / It can also be Called EAN - Participants are required to Predict demand for each of these style_IDs for SS19 and AW19 across stores.
Style_Color_ID - Represents the Colour of Each style or Style IDs
Discount - Discount offered on the Style
NSV - Net Sales Value
Sales_QTY - Represents the No of Styles sold at a particular store on a particular day.
SEASON - Represents the Season in which the sale happened
PROMOTION - Represents the If any promotion was offered (Yes/NO)
LIST_PRICE - List Price of the Style
COLOR - Represents the Colour of the Style
Size - Size of the Style
Launch_Date - The Date at which the product/Style was first launched (Gives an idea about the Age of the Style)
Department - Represents the Department to which the style belongs.
CATEGORY - Category of the Style
CAT_DESCP - Description of the Category
CLASS - Class of the Style
CLASS_DESP - Description about the Class of the Style
SUB_CAT - Subcategory of the Style
SUB_CAT_DESP - Description of the Sub Category
GENDER - Gender
MRP - Price of the Style
STANDARD_COST - Standard Cost of the Style
STYLE_ATTR_1 - Attribute which represents the style ( Ex: Round Neck, V-Neck etc for a Tshirt/Shirt)
STYLE_ATTR_2 -Attribute which represents the style ( Ex: Round Neck, V-Neck etc for a Tshirt/Shirt)
STYLE_ATTR_3 -Attribute which represents the style ( Ex: Round Neck, V-Neck etc for a Tshirt/Shirt)
Note: Null Values in STYLE_ATTR_1 to 3 represents the Specific style that does not belong to that attribute - Participants can create a single Style Attribute Column based on their understanding of the Data
Country - Country
State - State
Zone - Represents the Region (North, South )
Status - Status of the Store
STORE_TYPE - Represents the Type of the Store
GRADE - Grade to each of the Stores
------------------------------
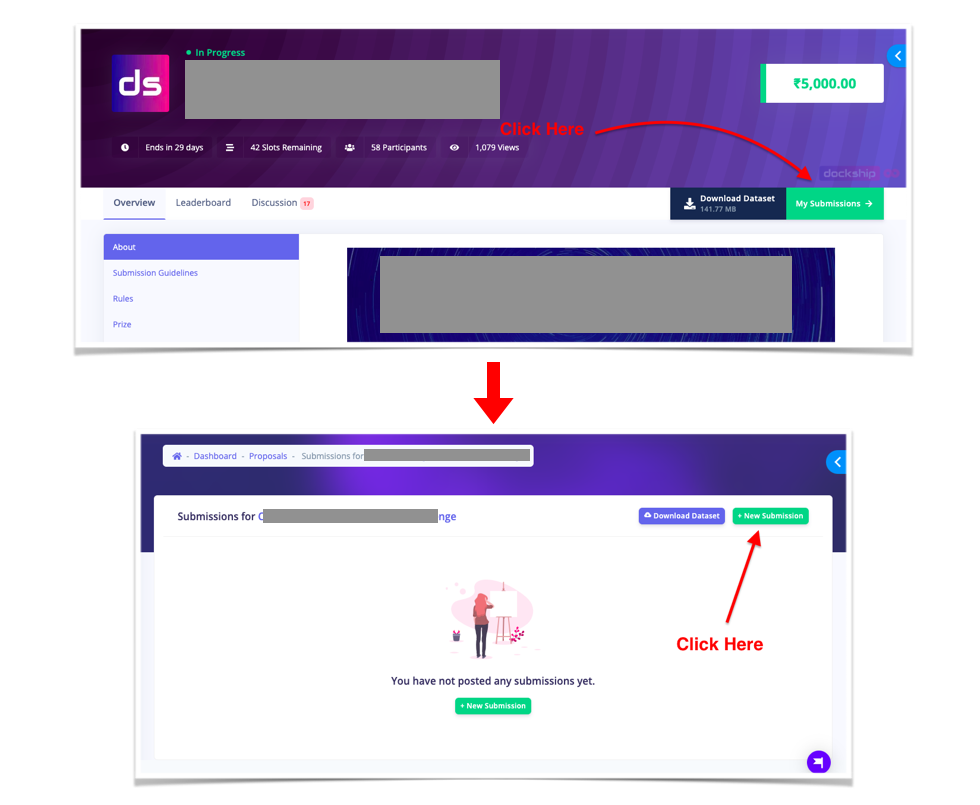
How to make a submission?
- Click on "My Submission"
- On the next page, click on "+ New Submission"
- Upload your CSV on the next page and click on "Submit for Review"
Please note:
- You must submit your CSV file by uploading the CSV in the "My Submissions" section of this challenge.
- Your submission will be auto-graded and you will be able to see your results instantly.
- If there is an error in the submission, your final score will be marked as 0.
Judgement
- Root Mean Squared Error (RMSE) will be used for evaluation
Rules
- Candidates topping the challenge will be sent to the next round of interview, where they will be asked a proper explanation on the approach they took to solve the challenge along with the details of the solution.
- The submission should be in a proper format as described by "Submission Guidelines".
- Late submission will not be accepted beyond the provided deadline (Indian Standard Time).
- Submission must not include any copyrighted code. If a violation is found, the submission will be instantly rejected.
- Plagiarism of code is strictly discouraged. If a violation is found, the submission will be instantly rejected.
Key Challenges for the participants
A. Accurately Predict the Demand for SS19 and AW19 for the Store-Style Combinations using the last 4 Seasons Data.
B. Can you predict the demand for Styles across stores that do not have any historical data?
C. What features play an important role for each of the styles (ex: MRP, Style Attributes etc), Candidates can use feature engineering to create additional features etc
- Feature Engineering
- Feature Importance
D. Can you accurately Cluster Similar styles across Similar Stores?
Reward:
- Full-time offer as mentioned in the package offering.
- If the candidate performs, Internship Offering with stipend Rs. 20,000 to Rs. 25,000 may be provided and on a good performance in the internship period, then the company may decide a PPO.
- Participants with at least once successful submission will receive certificates as well for their commendable effort
- Top 3 Participants will get a permanent place in Dockship's Hall of Fame.
Top 5 people will receive Dockship Gems:
- Rank 1: 250 💎
- Rank 2: 150 💎
- Rank 3: 100 💎
- Rank 4: 50 💎
- Rank 5: 50 💎
Challenge Started
Challenge Ended
